TL;DR: Tall code is better than Wide code
Equivalent JSON:
-
Wide code:
{"glossary":{"title":"example glossary","GlossDiv":{"title":"S","GlossList":{"GlossEntry":{"ID":"SGML","SortAs":"SGML","GlossTerm":"Standard Generalized Markup Language","Acronym":"SGML","Abbrev":"ISO 8879:1986","GlossDef":{"para":"A meta-markup language, used to create markup languages such as DocBook.","GlossSeeAlso":["GML","XML"]},"GlossSee":"markup"}}}}} -
Tall code:
{ "glossary": { "title": "example glossary", "GlossDiv": { "title": "S", "GlossList": { "GlossEntry": { "ID": "SGML", "SortAs": "SGML", "GlossTerm": "Standard Generalized Markup Language", "Acronym": "SGML", "Abbrev": "ISO 8879:1986", "GlossDef": { "para": "A meta-markup language, used to create markup languages such as DocBook.", "GlossSeeAlso": [ "GML", "XML" ] }, "GlossSee": "markup" } } } } }
And analysis is deeper than the look.
OLSD
It is hoped this campaign will raise OLSD awareness and improve support of OLSD-accessibility in automatic code formatters.
Obsessive Line Splitting Disorder (OLSD) reveals itself within code written by OLSD-affected people - they passionately split code lines.
If you noticed OLSD symptoms in someone, do not resist. Please, read and learn.
Paying increased attention to any code style is a disorder on its own.
However, the following analysis argues that OLSD-influenced code is not a style as in aesthetics. Instead, it is an instinctive pattern developed in deepening “symbiosis” between humans and computers.
Analysis
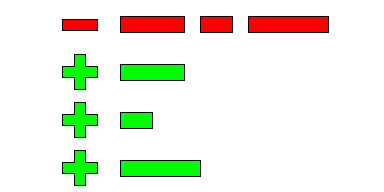
OLSD turns any existing code into the equivalent one by splitting lines into lists with constant indents.
The goals are:
- universal cross-tool integration;
- visual clarity.
False sense of complexity
Less code means less complexity (a good thing).
Any whitespaces keep code complexity constant, so does a line break.
Do not confuse increased line count of split lines with increased code complexity.
Bloody horizontal scrolling
There are two scrollings - horizontal ↔ and vertical ↕. And most of the existing UI conveniently works with vertical ↕ only.
Even a typical mouse has single vertical ↕ wheel - natural direction to scroll code which grows vertically.
There is no Page Left or Page Right keys either.
Mathematical formulas and expressions are historically written into single line with primitive single-character naming convention for density on a blackboard. Don’t modern mathematician all write software?
Compressed cryptic code on a whiteboard never lasts and never executes:
v a(D o, L<C> l, W t, S... a) {}
Maintainable code tend to have names expressively long for clairty.
Let’s see how OLSD you already are - take a look at this equivalent:
void anyFunctionWithLongArgumentList(double argumentOne, List<ArbitraryClass> argumentTwoAsList, WhateverClass argumentTree, String... otherArguments) {
}
That horizontal ↔ scrolling should annoy even normal healthy person.
Let’s not hold OLSD long and split lines:
void anyFunctionWithLongArgumentList(
double argumentOne,
List<ArbitraryClass> argumentTwoAsList,
WhateverClass argumentTree,
String... otherArguments
) {
}
Some OLSD treatments misleadingly suggest imagining wide monitors. Studies have shown - monitors can go wide, eye focus cannot.
Besides that, OLSD is strong among side-by-side code reviews addicts - displays are split in half vertically to use synchronous scrolling matching line numbers.
In short, rotate wide display 90° until its tall.
To improve accessibility of code for those impaired by OLSD, half-measures like this one can be seen:
void anyFunctionWithLongArgumentList(double argumentOne,
List<ArbitraryClass> argumentTwoAsList,
WhateverClass argumentTree,
String... otherArguments) {
}
Although each function argument is on a separate line,
the indent looks ridiculous.
Why does it have to be strlen("void anyFunctionWithLongArgumentList")-long?
To explain the ridicule of indenting arguments to their function name length, let’s extend this approach consistenly on entire function body:
int anyFunctionWithLongArgumentList(double argumentOne,
List<ArbitraryClass> argumentTwoAsList,
WhateverClass argumentTree,
String... otherArguments) { int localVar = 1;
int anotherLocalVar = 2;
boolean whateverLongVariableNameWhichShiftsIndentEvenFurther = argumentOne < 0 &&
argumentTwoAsList.isEmpty() &&
/************************/ argumentTree == null &&
/* WASTE OF REAL ESTATE */ otherArguments.length == 0;
/************************/
for(ArbitraryClass ac: argumentTwoAsList) { System.out.pringln(ac);
localVar++;
anotherLocalVar += 2; }
return 0; }
A rare healthy person would be tolerant to that above:
- Bloody horizontal scrolling has emerged again.
- Bloody variable length indent makes no sense.
Indent must be constant1 in length - every new line can have either no added indent or +/- single constant shift only:
line 1
line 2
line 3
line 4
line 5
line 6
wrong ugly 7
Consult the beauty:
int anyFunctionWithLongArgumentList(
double argumentOne,
List<ArbitraryClass> argumentTwoAsList,
WhateverClass argumentTree,
String... otherArguments
) {
int localVar = 1;
int anotherLocalVar = 2;
boolean whateverLongVariableNameWhichDoesNotAffectIndent =
argumentOne < 0 &&
argumentTwoAsList.isEmpty() &&
argumentTree == null &&
otherArguments.length == 0;
for(ArbitraryClass ac: argumentTwoAsList) {
System.out.pringln(ac);
localVar++;
anotherLocalVar += 2;
}
return 0;
}
There is no known reason to avoid constant indent anywhere.
Unnecessary changes are evil. Variable indent triggers unnecessary whitespace changes in “innocent” lines (for example, when function name changes):
void culpritWhichIndentChanges(
int innocent1,
int innocent2,
int innocent3
)
void culprit(
int innocent1,
int innocent2,
int innocent3
)
-void culpritWhichChangesIndent(
- int innocent1,
- int innocent2,
- int innocent3
+void culprit(
+ int innocent1,
+ int innocent2,
+ int innocent3
)
What are these innocent* victims for?
Constant indent keeps innocent* safely unchanged:
-void culpritWhichChangesIndent(
+void culprit(
int innocent1,
int innocent2,
int innocent3
)
Avoiding unnecessary changes goes into deep analysis in the next section.
Paranoid change tracking
Writing code less prone to merge conflicts reduces the ultimate cost - human time. The opposite causes merge conflicts and develops OLSD.
Ideally, two changes for unrelated features should cause no merge conflicts.
To see direction leading to the problem, imagine an extreme case - entire application code is written in a single line (“single line app”). No changes can be made in parallel because every change causes conflict and conflict causes rewrite of all lines (because it’s “single line app”).
A less extreme example which can constantly be found in the wild:
enum SupportedCodes {
CODE_ZERO, CODE_1, CODE_TWO, CODE_THREE, CODE_FOUR, CODE_FIVE, CODE_SIX, CODE_SEVEN, CODE_EIGHT, CODE_NINE; //...
};
Regardless how many versions/years back CODE_1 made into SupportedCodes,
git blame for the code above will always show
only the latest change of the entire enum set.
Without paying human time and scanning both +/- lines,
the patch literally says “everything was changed”:
enum SupportedCodes {
- CODE_ZERO, CODE_1, CODE_TWO, CODE_THREE, CODE_FOUR, CODE_FIVE, CODE_SIX, CODE_SEVEN, CODE_EIGHT, CODE_NINE; //...
+ CODE_ZERO, CODE_ONE, CODE_TWO, CODE_THREE, CODE_FOUR, CODE_FIVE, CODE_SIX, CODE_SEVEN, CODE_EIGHT, CODE_NINE; //...
};
Such formatting for enum may rightfully cause
a sudden OLSD attack even among resistant people.
Let’s please an OLSD-person with harmonized enum formatting:
enum SupportedCodes {
CODE_ZERO,
- CODE_1,
+ CODE_ONE,
CODE_TWO,
CODE_THREE,
CODE_FOUR,
CODE_FIVE,
CODE_SIX,
CODE_SEVEN,
CODE_EIGHT,
CODE_NINE,
//...
;
};
Statistically speaking, the more line is responsible for - the more likely it is changed:
-
scope of code reviews grow larger (more bugs to slip through)
-
true authors will not be seen (to ask, blame or praise) in source
HEAD -
automatic merging is more likely to fail (more human time to waste)
The “single line app” extreme case is extreme,
but there are syntaxes where lines are impossible2 to break
(e.g. CSV, Markdown tables, or even grep-able log records)
resembling visual formatting.
Then, even changes touching independent columns
will make entire rows unmergeable
forcing human-time-costly rework.
To see direction leading to the solution, imagine another extreme case - entire application code is written with single lexical tokens per line.
Are we talking about line-wise single responsibility principle here?
A
classline should have only one reason to change.
To avoid splitting lines on every token, consider token groups which rarely go separately (e.g. variable type and id, or function qualifiers and id).
Cross-border first-class citizen: line
Two observations:
-
The syntax of every language extends plain text (by recognizing lexical tokens).
-
And plain text syntax recognizes line as the only compound processing unit (the smaller is already individual “atomic” character).
There is an exceptional imbalance - 1 versus N (language parser versus all other tools) whether a tool works at token level or line only.
For example:
-
Many step-by-step debuggers evaluate single line at once.
// function argument evaluation someFunction ( someContainer.isEmpty(), this.someField == null, someArgument + 2 )Options to evaluate specific part of long overloaded lines may need special tricks.
-
Code coverage tools show line-by-line reports.
// short-circuit evaluation if ( someContainer.isEmpty() && this.someField == null )To improve coverage, partially evaluated long overloaded lines require figuring out which part was partial. Simple short lines are unlikely to be partially evaluated - no investigation, human time saved.
-
Error message by language parser often reports line only.
Moreover, line is a universal pointer in IDE/editor integration with any reporting tool to auto-highlight relevant code.
-
Single line comment syntax is more wide-spread than other options.
And single line comment can easily target more relevant code part when expression components are split per line.
double a = abs( // We use `3` out of good mood. 3 * sin(y) - // There is no reason why `7`. 7 / (x - 2) ) / 2; -
Code analytics relies on lines to derive many statistical values.
Getting closer to “single responsibility per line” turns line count into cleaner “statistics of complexity”3.
Lines do not inflate the code (no added redundancy) while future non-architectural changes appear more focused and comprehensible.
-
Text editors…
Even text editors hardly support “go to column” shortcuts - only lines are truly “go to” addressable.
There are even special shortcuts to delete single line. What kind of convenience does it provide if code is not OLSD-friendly?
And, again, points detailed in previous sections:
-
Patches look clearer and more comprehensible.
-
More code history gets preserved avoiding overrides.
-
Only relevant lines tend to be touched for code review saving human time.
-
Automatic mergeability is more likely.
Once lines are viewed as nested lists, the mental block is removed and many normal people start growing lists vertically exhibiting behavior attributed to OLSD.
Order of priority
Any coder should “please” 3 groups:
-
Parsers are pleased unavoidably by writing correct syntax.
-
Other tools are pleased by splitting more code lines with constant indent.
-
Other coders are pleased by decorative whitespaces for style.
And OLSD influence nervous system to respect each group in exactly that order of priority.
What’s left for style?
OLSD turns humans significantly insensitive to stylish whitespacing.
Qualities are paramount, therefore, style is disregarded until after:
-
Enough lines are broken
This is not a style, this makes tools work for human.
-
Constant indent is applied
This is not a style, this makes sense.
To explain what stylish whitespacing is, it’s simpler to explain what it is not:
-
Places for line breaks.
Not every lexical token deserves successive line break.
These are the must (repetitive token groups):
- Statements (nested in loops/conditions)
- Function arguments
- Calls in method chaining
- Implemented interfaces
- Class members
- Declared exceptions
- XML tag attributes
- … essentially, any list.
The others are stylish whitespacing.
-
Places for constant indent.
Indent or not indent?
These are the must (to depict relationship between lines):
- “is child of”
- “includes”
- “belongs to”
The others are stylish whitespacing.
Because stylish whitespacing is not a quality, style deviations are highly tolerable by OLSD-affected.
What about the classical holy war of curly braces?
void a() {
//...
void a()
{
//...
This holy war must be caused by different disorders.
OLSD is mostly irrelevant to changes in line breaks between tokens within single semantic group (e.g. starting function, or loop, or class, …).
Bonus Thought: Troublesome Erratic Trailing Delimiter (TETD)
All code is a list of lexical tokens - the very existence of OLSD manifest it with strong uncomfortable sensation to break lines between these list items. Line break (a whitespace), however, is not a common syntactic choice for list item delimiter - additional token is used in between:
-
Function argument list use
,(comma) as a delimiter:someFunction ( someContainer.isEmpty(), this.someField == null, someArgument + 2 ) -
Boolean expression components are delimited by boolean operators (e.g.
&&~ANDhere):if ( someContainer.isEmpty() && this.someField == null && someString.startsWith("whatever") )
The list goes on…
Now, notice the syntactic annoyance - the Troublesome Erratic Trailing Delimiters (TTD)!
Why Troublesome? Adding new items at the end of a list always forces us to change the innocent previous item first:
if (
someContainer.isEmpty() &&
this.someField == null &&
- someString.startsWith("whatever")
+ someString.startsWith("whatever") &&
+ isNotFairToInoncent == true
)
All these sacrifices exist simply because list delimiter (&&)
demands subsequent list item. Think! This need is artificial
(made up by healthy population which does not care about OLSD).
Why Erratic?
{
int a = 1;
double b = someFunction(a);
;
;
; // <= Blanks in `;`-delimited list of statements before `}` are valid!
}
You don’t bother to remove ;
from the last statment in a block before closing }, do you?
Then, why bother removing last && or + in boolean/arithmetic expression?
It may seem that operators like
boolean && or arithmetic + are not list delimiters.
And what would be the argument against && being list delimiter?
Why not accept the opposite?
What if all delimiters are operators for concatenating different lists?
If mathematicians were coders for centuries, they would agree to compile tail operators out or treat them no-op by now:
// List of lines generically ending with `+`:
int result =
a + b * c +
d * e + f +
h - i - j +
k + l * n + // <= Last `+`-delimiter with "blank operand" can be no-op!
;
TETD is utterly irregular unnecessary special case:
-
Sometimes TETD is a must (
;at the end of statment). -
Sometimes TETD is a must-not (
+in arithmetic expression). -
Sometimes it is optional.
It’s surprising that (e.g. in current Java syntax)
enumitems can actually keep troublesome errant trailing delimiter:enum SupportedCodes { CODE_ZERO, CODE_ONE, //... CODE_EIGHT, CODE_NINE, CODE_TEN, // <= Hey! Designed by OLSD. // <= Blank element after last comma is compiled out. ; };
Not only TETD is annoying, the way such special cases are inconsistently maintained perhaps holds us back as species.
-
Constant indent just has to be that: constant (e.g. 1, or 2, … or 7 spaces).
A line never increments/decrements indent by more than this constant. Any indent level should be reachable by single increments - forward or backward:
level 1 level 3 # reachable from below level 2 level 1Even 0 is still a constant (degenerate) indent.
And don’t get mental, but 4 spaces is a widely used, even standardized and enforced in some languages.
Another point is “spaces not tabs” simply because spaces are shown the same way everywhere regardless of the settings (which may not be accessible, for example, on the web). ↩
-
Examples of “unbreakable line” syntaxes are often for data formats only:
-
CSV records are widely used due to open-ability by Excel and ease of parsing. Avoid them for any long-term use, if possible, or generate (e.g. from JSON, YAML, …).
-
Log records are often kept as single line record (to associate timestamps, level, message, etc.) to easily
greprelevant lines only.They are less relevant in the context of OLSD because nobody changes them and most of their data are never read.
-
Gherkin tables used for Cucumber tests. When tables are comprehensive enough (good thing), they may impair parallel development (bad thing) because:
-
(A) branch is incomplete until tests (tables) are done
-
(B) every changed test is a source of rework during table merging
-
-
Markdown tables of any considerable size turn wiki into pain for concurrent modifications.
-
-
With nearly single responsibility per line, line count directly translates into complexity managed manually in code:
- list of arguments
- list of data fields
- expression components to evaluate
- steps to execute
- …