This post pays attention to one particular service design promising “ergonomic” benefits - ease of reasoning and trusted correctness via unit-testing.
The terms may differ (highlighting additional properties), but the ideas are interleaved:
-
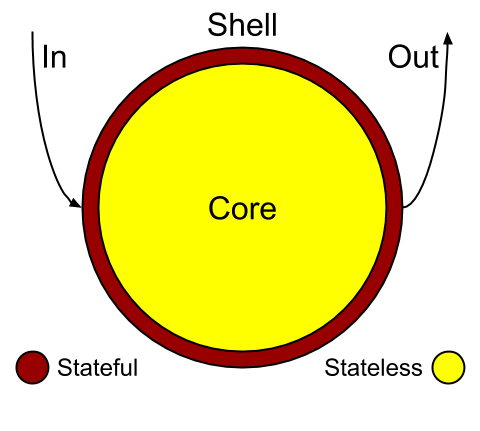
Imperative Shell - Functional Core
“This functional Core is surrounded by a Shell of imperative code: it manipulates stdin, stdout, the database, and the network, all based on values produced by the functional Core.”
-
Mutable Shell - Immutable Core
“This Shell comes into play when the Core finishes working; it doesn’t contain any business logic.”
“Ideally, try to bring it [Shell] to the cyclomatic complexity of 1. In other words, try not to introduce any conditional operators (
ifstatements) in it.” -
Reactive Shell - Functional Core
“The idea is to split the [Core] code that takes decision, what side effect to perform, from the [Shell] code taking action, what actually performs the effect.”
Essense
All references above boil down to splitting a service into Shell and Core.
Such separation is not new by intuition. Every component has its “Shell” for input and output and “Core” for processing.
The new point here is the split of responsibilities - clear separation of decision making (Core) and state mutations (Shell):
Shell:
- reactive/imperative
- has least of the overall complexity
- is mostly plumbing
- only transfers state values (stateful)
- always calls Core
- framework-bound
Core:
- functional
- has most of the overall complexity
- is mostly domain logic
- only generates state values (stateless)
- never calls Shell
- library-bound
Addressed problems
Let’s list drawbacks when any part of the system can arbitrarily read/write state of any other:
-
The output of operation is hard to ensure or reason about by looking at input only (requires careful internal inspection).
The result appears non-deterministic and non-reproducible.
-
Testing needs setting up test doubles like mocks (while, otherwise, pure functional logic would be useable in tests as is).
-
Domain logic cannot be reused without rework because it relies on calls to external services embedded internally.
An abstraction layer to access state may help, however, this still turns out to be cleaner with Shells.
Reality
If we picture implementation of other possible services in terms of Shell and Core, we will notice that Core takes on the responsibility of Shell to access the state (see picture’s left side).
To fix that and achieve perfect responsibility split, the “imperfect” service can be broken down into multiple1 Cores interacting through Shells (see picture’s right side).

In fact, if the responsibility of accessing state is not separated out of Core, terms Shell and Core stop showing any difference in our context.
Functional Core - How?
Notice that every operation within Core turns non-blocking2 because it does not need to depend on any shared state - required state is explicitly passed from the Shell.
Now, look at this the other way around… How do we achieve perfect Core?
Every time there is a need by Core for (potentially) blocking request to get some additional state from Shell, such request can be split into two purely functional operations:
-
The one before potentially blocking request.
Core returns to Shell to store intermediate state.
-
The one after potentially blocking request.
Shell calls Core providing the previously stored intermediate state.
Think of State Machine to keep track of intermediate states (like “pending data”) and transition between them while avoiding blocking calls within Core.
Reactive Shell - Why?
Here “reactive” refers to etymology - the origin of the word (otherwise, the meaning tends to be rather diluted):
- re-active ~ active only in response to an external action
- being notified about an event to process (opposite to actively polling for an event)
- Hollywood Principle
Shell can naturally be designed reactive - it already “checkpoints” intermediate state between calls to Core (as mentioned above because Core is stateless and functional). Shell can resume processing only when new possibility arise.
Another motivation for Shell’s reactive-ness3 is hiding complexity in common frameworks via notification calls to Shell (rather than managing data exchange directly via libraries). Except some service-specific data conversions, Shell’s responsibility tends to be generic and reusable enough to be “outsourced” to some external framework. Shell should be “simple” as in “simple to use”.
Shell’s code can avoid unit-testing by keeping it trivially simple (or even configuration only) together with low defect risk in it. Ideally, it is changed with target environment and only integration-tested.
Conclusion: Pros and Cons
There are definitely applicability boundaries for such architecture. However, adoption issues may not be related to the split into Shells and Cores in particular - it may well be other common problems of complex domains.
So, with all other things being equal, let’s think of a difference (reactive) Shells and (functional) Cores can bring when such split is done…
Pros:
-
Clearer reasoning - faster development.
Assumptions about code are very explicit because complex Cores only rely on (again, explicit) input and all state changes contained only in simple Shells.
-
Code testability.
Testing production code in Cores directly without any mocking.
The source of risk left for defects (outside of unit tests) is in simple Shells.
-
Code mobility.
Cores encapsulate domain logic and they can be shipped as functional libraries.
Switch Shells of the same Core to achieve different setups - monolithic or distributed applications, using one framework or another, providing persistence layer or staying distributed in-memory.
-
Validation at the earliest convenience.
Validation should be done before irreversible changes to state are about to be made.
With Shells and Cores, the area to place validating decision opens wide - entire execution until it is about to be committed in Shell. It only becomes a matter of optimization (fail fast) and some sense of order.
-
Bonus: relative ease of tracking down performance bottlenecks.
Reactive Shells become the single point per service for measurements of external data exchange bottlenecks.
Internal processing speeds within functional Cores can be trivially measured even during unit testing (remember: no mocks are used!).
Cons:
-
Additional efforts to avoid quick and dirty hacks ~ pain of discipline.
It might be tempting to make exceptions and put exchange of state into parts of the Core (e.g. access to shared cache). Then think - all Pros (reasoning, testability, mobility, …) would be gone.
See also
-
We avoid touching on “Monolith vs Microservices” because:
-
Tight coupling between separate services may render entire system as a monolith (hard to evolve independently) while still allowing simpler reasoning about individual sub-services. In other words, avoiding monolith is a separate concern.
See also Microservices Split Criterion.
-
Technically, the state may be stored completely in memory (transient) and all sub-services may never reveal themselves outside single OS process.
Events which Shell reacts to may be reduced to simple function calls by “gluing” framework (anything from Observer Pattern to JEE/Spring container). In this case, the system is not distributed (as microservices imply) while it can still be easily transformed into distributed one by “attaching” different Shell (e.g. to communicate over a network) to all participating Cores.
-
-
Potentially blocking operations are those accessing shared state (in-memory via locks, I/O or network).
What does it mean? Accessing state means that operation does not belong to Core. All explicit thread synchronization or calls to blocking operations has to be implemented in Shell (better - in a framework surrounding it). ↩
-
Just to be precise, reactive is a programming model allowed by external APIs. Shells should ideally seek to rely on such APIs.
Under the hood of APIs, any kind of non-reactive implementation may hide (e.g. background timer-based polling). ↩