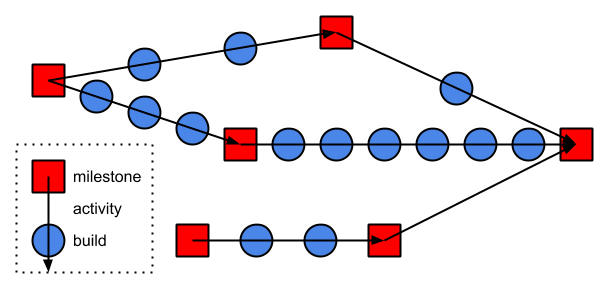
"Inter-dependent activities with milestones and intermediate builds"
In short, the two approaches are thought of as:
Waterfall: a complex process of inter-dependent milestones to build an “aircraft carrier” instance.
Agile: independent simple step to get an immediate result (hopefully incremental).
Most of the arguments about their differences seem bogus or pointless to me.
Instead of “waterfall vs agile”, there is only one fundamental factor impacting every development -
the instance build cost.
Instance Build Cost
Effects on planning/engineering:
If you are building a house, the cost is so high that you only build this house once - suggesting a waterfall mode.
If you are 3D-printing a house, afford few throw-away versions before the final one - suggesting an agile mode.
And if something is independent, regardless of waterfall or agile, it is instantly done. Otherwise, what is it waiting for (depending on)?
Normally, I consider both:
build cost - the higher the build cost, the fewer feedback prototypes to see if the direction is right;
dependency graph - the more dependencies, the “harder” it is to reach the target.
But if you think just a bit, these factors are not even orthogonal -
describing dependencies means zooming in on the build cost (breaking it down).
Moving to the contrasts:
To build a skyscraper version, you need 100000000s of dollars and 10s of months of tracking dependent activities.
To build a software version, an automated pipeline does it in minutes adding a few dollars to a shared bill.
In other words, “agility” is highly conditional -
you do not decide to “go agile”.
Instead, you assess the build cost and select the right mode.
Both waterfall and agile belong to each other in dualism like yin and yang -
just two extremes for low and high build costs.
Agile emerged in software development and became ubiquitous
because of extremely low build cost via automation,
not because of the trendy popular rituals.
When does splitting a monolithic system into multiple services make sense?
When does it stop making any sense?
Connections as dependencies between services
Services depend on some input to
produce the output they were created for.
Based on these “communication lines” (dependencies),
splitting a service (or not) into multiple ones can be objectively rationalized.
Criterion: time spent to verify system
Eventually, what matters is the overall human time spent
on making changes to the system.
Now, the change in a system is only useful
when it is finally verified1.
The efforts on verification grow with the test space.
When we compare monolith and multiple services,
we compare test space difference before and after the split.
Abstraction
Boolean function
The services are simplified to compute mere boolean functions
where every “input line” is 1-bit boolean value.
This abstraction is easy to imagine and universal for our purpose.
The system as a whole
(whether it is multiple services or monolith service)
has fixed 12 inputs and 1 output.
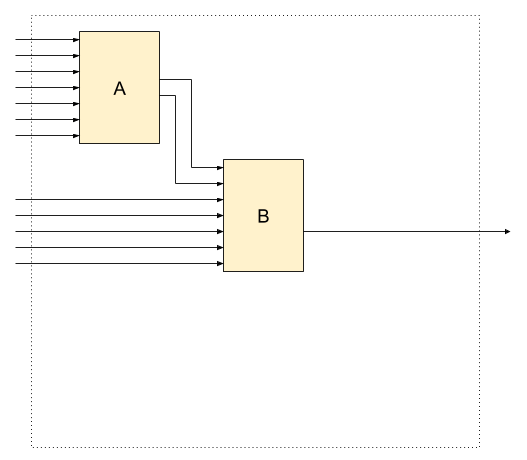
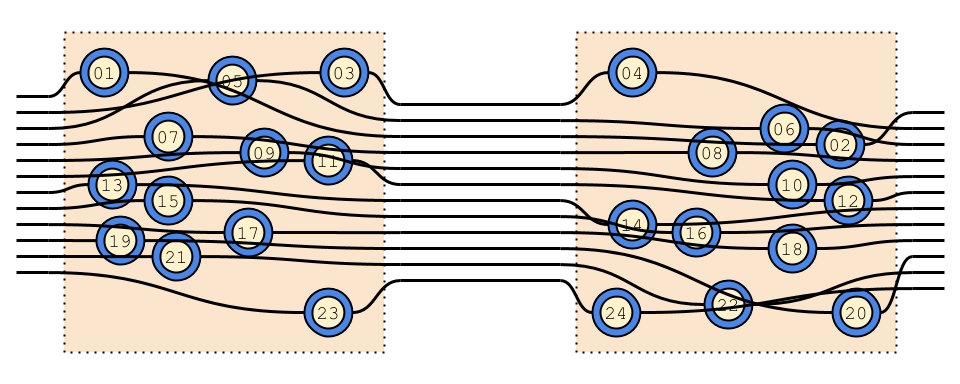
Initial system - boolean function with 12 inputs and 1 output
We compare initial monolith and
its split into two services (A and B).
Stateless services
All services (boolean functions) are stateless.
Even if they were not, a state could be modeled by some input data.
If we consider some input data as a state,
it constitutes identical test space
and does not change results in principle.
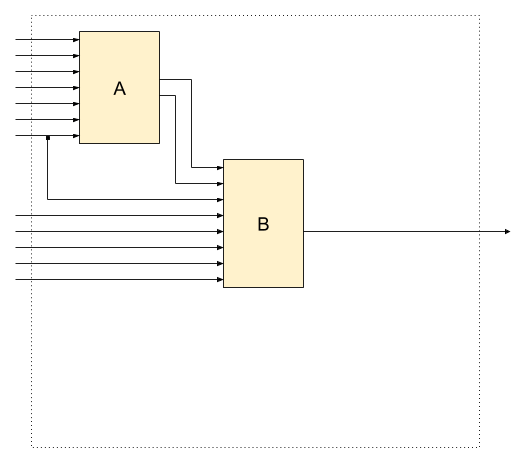
Expression dependencies
Whether monolith service is rather split-able or rather not
depends on its boolean function.
What kind of data dependencies exists between expressions computing the function.
How (where) do we split these expressions.
// Shared input[1].// Independent.booleanservice1(booleaninput[]){booleanpotential_service_a=input[1]||input[7];booleanpotential_service_b=input[1]&&input[8];returnpotential_service_b;}// No shared input.// Inter-dependent.booleanservice2(booleaninput[]){booleanpotential_service_a=input[2]||input[7];booleanpotential_service_b=input[3]&&input[8]&&potential_service_a;returnpotential_service_b;}
We don’t care about exact expression for each case,
we simply assume it can be anything
suitable for that particular case.
Test space
Test space is determined purely by the input permutations.
There cannot be more output variations than input.
Regardless of internal complexity, a service is only required
to respect external contracts agreed with other services.
Neglected integration
Making equivalent inter-dependent changes in distributed services
is obviously more time-consuming.
We neglect that.
Why? Even before we start adding this extra cost,
the split itself has to show its benefits.
For the same reason, we also neglect integration testing.
Even when the split is already justified,
integration testing is normally limited to
“communication lines” (right “wiring”)
and avoids thorough input permutations
(which is much more efficiently performed by unit test anyway).
We have test space explosion from initial 2^12=4096 to 4096+16777216=16781312!
Observation
What matters is the number of dependencies per individual service.
The test efforts exponentially grow with that number.
Notice that splitting monolith service into multiple ones
may require more dependencies (“communication lines”) for some services.
These lines were hidden in the monolith.
Now they are part of the explicit contract between services
and require test coverage.
This is when splitting does not make sense.
Even if the number of dependencies before and after the split is equivalent,
the nature of the dependencies (internal or external)
still makes a considerable impact on maintenance cost.
Internal dependencies within monolith cost less human time to manage
due to automation:
compile-time checks
refactoring tools
fast lightweight unit testing
External dependencies across multiple services:
have fewer automatic support
involve resource-intensive integration testing
Distributed Complications
Latencies
Frequent round trips for external data will bring the performance down.
Failures
Multiple services fail independently.
To recover resiliently,
handling failures explodes testing space further.
Monolith service fails as a whole.
It may be easier to distribute whole monoliths for redundancy.
Whole monoliths use reliable communication with itself
reducing test space by impossible internal communication failures.
Conclusion
The 1-bit data dependencies is the minimum to
differentiate one case from another.
Real world input cases will have to provide at least that
(to select different code branch).
Any attempt for full input permutations is often beyond practically possible.
This is only bad for the real world,
but does not make this argument invalid.
The total test space (for boolean expresions) grows as a polynomial:
A*2^(n) + B*2^(n-1) + C*2^(n-2) + ...
A - total number of services with (highest number) n dependencies.
The split of monolith should at least try to reduce highest number
n of dependencies met in any service.
Depending on the internal dependencies, it may be impossible to simplify
system by splitting it into multiple services.
Graph Clustering Algorithms resolve this optimization problem
where it is possible.
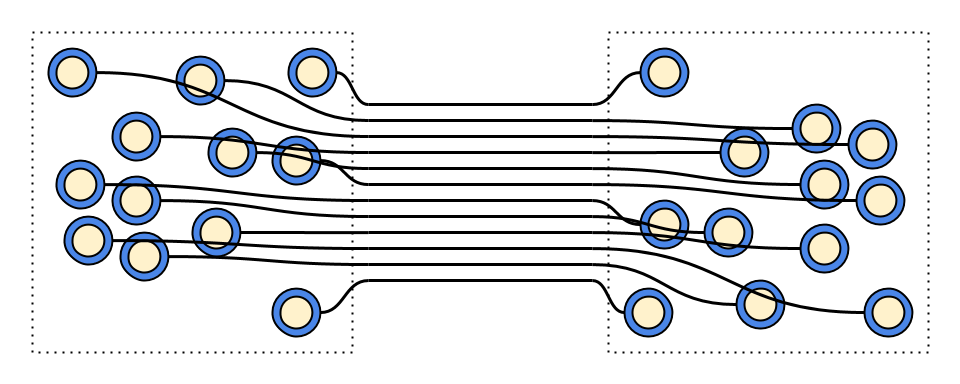
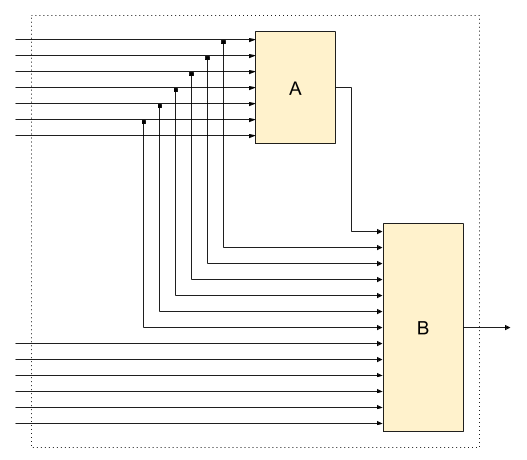
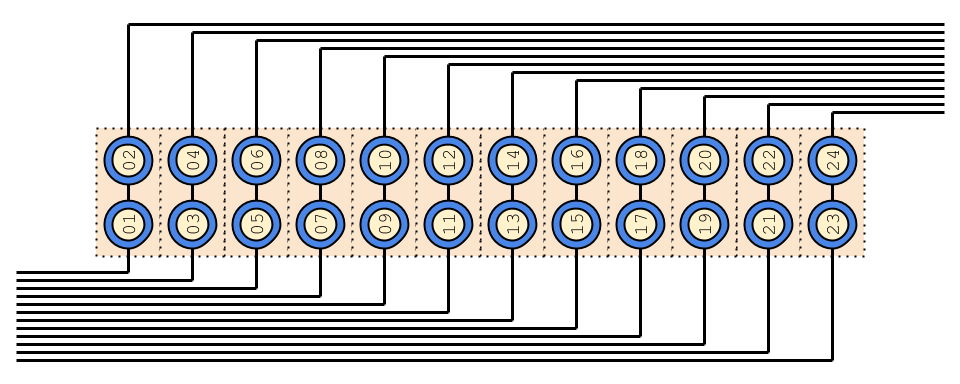
Non-optimal split into 2 tightly coupled services
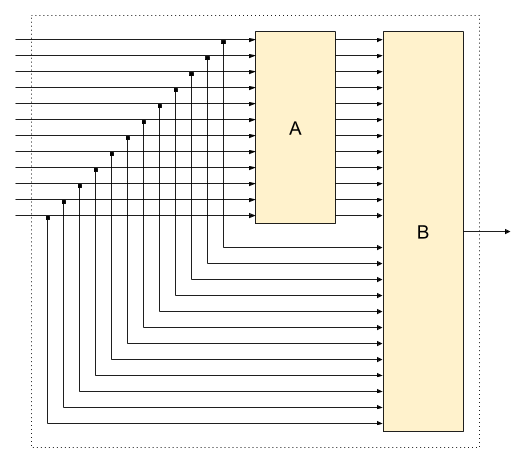
Optimal split into 12 independent services
Test space:
2 services
12 services
2*2^12=8192
12*2^1=24
This somewhat quantifiable approach to justify splitting.
The cost reduction is purely based on testing efforts
(let alone avoiding other issues of distributed systems).
Is it all surprising?
There are reasons why all biological brains tend to be
co-located/integrated into the single monolithic head
rather than distributed across the entire body.
If our brain was distributed,
the wiring would be exhaustive to support.
Now, what we have as distributed services are
“loosely coupled across” yet “tightly integrated within” body parts:
the brain itself serves decision making
legs serve kicking
hands serve grabbing
This may not be obvious, but most of the time human spend on during
changes is their verification. In fact, the very change itself
is made only after some thought experiment suggested the change
seemingly produce desired effect. ↩
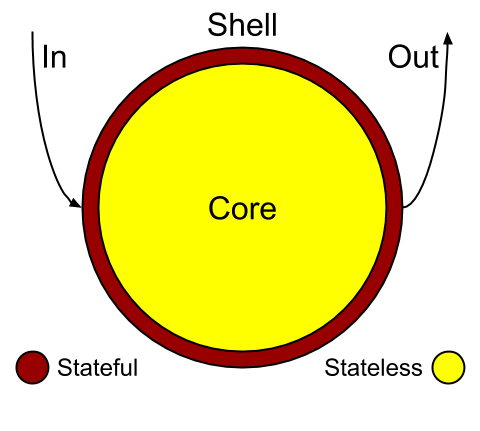
“This functional Core is surrounded by a Shell of imperative code:
it manipulates stdin, stdout, the database, and the network,
all based on values produced by the functional Core.”
“This Shell comes into play when the Core finishes working;
it doesn’t contain any business logic.”
“Ideally, try to bring it [Shell] to the cyclomatic complexity of 1.
In other words, try not to introduce any conditional operators
(if statements) in it.”
“The idea is to split
the [Core] code that takes decision, what side effect to perform,
from the [Shell] code taking action, what actually performs the effect.”
Essense
All references above boil down to splitting a service into Shell and Core.
Such separation is not new by intuition.
Every component has its “Shell” for input and output and “Core” for processing.
The new point here is the split of responsibilities -
clear separation of decision making (Core) and state mutations (Shell):
Let’s list drawbacks when any part of the system can arbitrarily
read/write state of any other:
The output of operation is hard to ensure or reason about by
looking at input only (requires careful internal inspection).
The result appears non-deterministic and non-reproducible.
Testing needs setting up test doubles like mocks
(while, otherwise, pure functional logic would be useable in tests as is).
Domain logic cannot be reused without rework
because it relies on calls to external services embedded internally.
An abstraction layer to access state may help, however,
this still turns out to be cleaner with Shells.
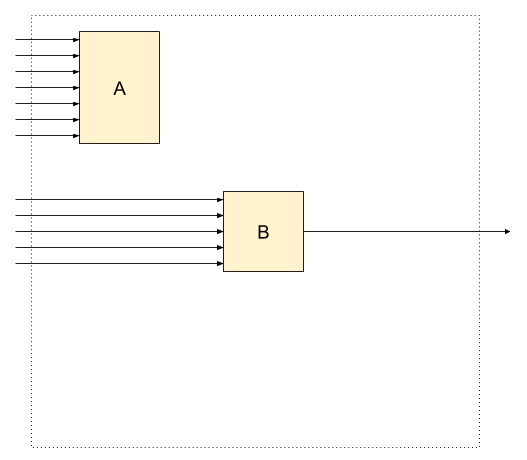
Reality
If we picture implementation of other possible services
in terms of Shell and Core,
we will notice that Core takes on the responsibility of Shell to access
the state (see picture’s left side).
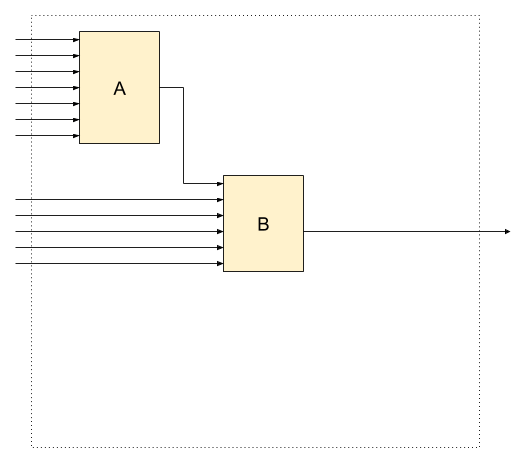
To fix that and achieve perfect responsibility split,
the “imperfect” service can be broken down into multiple1 Cores
interacting through Shells (see picture’s right side).
Splitting service into Shells and Cores
In fact, if the responsibility of accessing state is not separated out of Core,
terms Shell and Core stop showing any difference in our context.
Functional Core - How?
Notice that every operation within Core turns non-blocking2
because it does not need to depend on any shared state -
required state is explicitly passed from the Shell.
Now, look at this the other way around… How do we achieve perfect Core?
Every time there is a need by Core for (potentially) blocking request to
get some additional state from Shell, such request can be split into two
purely functional operations:
The one before potentially blocking request.
Core returns to Shell to store intermediate state.
The one after potentially blocking request.
Shell calls Core providing the previously stored intermediate state.
Think of State Machine to keep track of intermediate states
(like “pending data”) and transition between them
while avoiding blocking calls within Core.
Reactive Shell - Why?
Here “reactive” refers to etymology - the origin of the word
(otherwise, the meaning tends to be rather diluted):
re-active ~ active only in response to an external action
being notified about an event to process
(opposite to actively polling for an event)
Shell can naturally be designed reactive -
it already “checkpoints” intermediate state between calls to Core
(as mentioned above because Core is stateless and functional).
Shell can resume processing only when new possibility arise.
Another motivation for Shell’s reactive-ness3 is hiding complexity
in common frameworks via notification calls to Shell
(rather than managing data exchange directly via libraries).
Except some service-specific data conversions,
Shell’s responsibility tends to be generic and reusable enough
to be “outsourced” to some external framework.
Shell should be “simple” as in “simple to use”.
Shell’s code can avoid unit-testing by keeping it trivially simple
(or even configuration only) together with low defect risk in it.
Ideally, it is changed with target environment and only integration-tested.
Conclusion: Pros and Cons
There are definitely applicability boundaries for such architecture.
However, adoption issues may not be related to
the split into Shells and Cores in particular -
it may well be other common problems of complex domains.
So, with all other things being equal, let’s think of a difference
(reactive) Shells and (functional) Cores can bring when such split is done…
Pros:
Clearer reasoning - faster development.
Assumptions about code are very explicit because
complex Cores only rely on (again, explicit) input and
all state changes contained only in simple Shells.
Code testability.
Testing production code in Cores directly without any mocking.
The source of risk left for defects (outside of unit tests)
is in simple Shells.
Code mobility.
Cores encapsulate domain logic and they can be shipped as
functional libraries.
Switch Shells of the same Core to achieve different setups -
monolithic or distributed applications,
using one framework or another,
providing persistence layer or staying distributed in-memory.
Validation at the earliest convenience.
Validation should be done before irreversible changes to state
are about to be made.
With Shells and Cores, the area to place validating decision opens wide -
entire execution until it is about to be committed in Shell.
It only becomes a matter of optimization (fail fast) and
some sense of order.
Bonus: relative ease of tracking down performance bottlenecks.
Reactive Shells become the single point per service for
measurements of external data exchange bottlenecks.
Internal processing speeds within functional Cores can be trivially
measured even during unit testing (remember: no mocks are used!).
Cons:
Additional efforts to avoid quick and dirty hacks ~ pain of discipline.
It might be tempting to make exceptions and put exchange of
state into parts of the Core (e.g. access to shared cache).
Then think - all Pros (reasoning, testability, mobility, …)
would be gone.
We avoid touching on “Monolith vs Microservices” because:
Tight coupling between separate services may render entire system
as a monolith (hard to evolve independently) while still allowing
simpler reasoning about individual sub-services. In other words,
avoiding monolith is a separate concern.
Technically, the state may be stored completely in memory (transient)
and all sub-services may never reveal themselves outside
single OS process.
Events which Shell reacts to may be reduced
to simple function calls by “gluing” framework
(anything from Observer Pattern to JEE/Spring container).
In this case, the system is not distributed (as microservices imply)
while it can still be easily transformed into distributed one by
“attaching” different Shell (e.g. to communicate over a network)
to all participating Cores.
Potentially blocking operations are those
accessing shared state (in-memory via locks, I/O or network).
What does it mean?
Accessing state means that operation does not belong to Core.
All explicit thread synchronization or calls to blocking operations
has to be implemented in Shell (better - in a framework surrounding it). ↩
Just to be precise, reactive is a programming model allowed by
external APIs. Shells should ideally seek to rely on such APIs.
Under the hood of APIs, any kind of non-reactive implementation may hide
(e.g. background timer-based polling). ↩
{"glossary":{"title":"example glossary","GlossDiv":{"title":"S","GlossList":{"GlossEntry":{"ID":"SGML","SortAs":"SGML","GlossTerm":"Standard Generalized Markup Language","Acronym":"SGML","Abbrev":"ISO 8879:1986","GlossDef":{"para":"A meta-markup language, used to create markup languages such as DocBook.","GlossSeeAlso":["GML","XML"]},"GlossSee":"markup"}}}}}
Tall code:
{"glossary":{"title":"example glossary","GlossDiv":{"title":"S","GlossList":{"GlossEntry":{"ID":"SGML","SortAs":"SGML","GlossTerm":"Standard Generalized Markup Language","Acronym":"SGML","Abbrev":"ISO 8879:1986","GlossDef":{"para":"A meta-markup language, used to create markup languages such as DocBook.","GlossSeeAlso":["GML","XML"]},"GlossSee":"markup"}}}}}
It is hoped this campaign will raise OLSD awareness and improve support of
OLSD-accessibility in automatic code formatters.
Obsessive Line Splitting Disorder (OLSD)
reveals itself within code written by OLSD-affected people -
they passionately split code lines.
If you noticed OLSD symptoms in someone, do not resist.
Please, read and learn.
Paying increased attention to any code style is a disorder on its own.
However, the following analysis argues that OLSD-influenced code is
not a style as in aesthetics.
Instead, it is an instinctive pattern developed
in deepening “symbiosis” between humans and computers.
Analysis
Line breaks per each token group
OLSD turns any existing code into the equivalent one by
splitting lines into lists with constant indents.
The goals are:
universal cross-tool integration;
visual clarity.
False sense of complexity
Less code means less complexity (a good thing).
Any whitespaces keep code complexity constant, so does a line break.
Do not confuse increased line count of split lines
with increased code complexity.
Bloody horizontal scrolling
There are two scrollings - horizontal ↔ and vertical ↕.
And most of the existing UI conveniently works with vertical ↕ only.
Even a typical mouse has single vertical ↕ wheel -
natural direction to scroll code which grows vertically.
There is no Page Left or Page Right keys either.
Mathematical formulas and expressions are historically
written into single line with primitive single-character naming convention
for density on a blackboard.
Don’t modern mathematician all write software?
Compressed cryptic code on a whiteboard never lasts and never executes:
va(Do,L<C>l,Wt,S...a){}
Maintainable code tend to have names expressively long for clairty.
Let’s see how OLSD you already are - take a look at this equivalent:
Some OLSD treatments misleadingly suggest imagining wide monitors.
Studies have shown - monitors can go wide, eye focus cannot.
Besides that, OLSD is strong among side-by-side code reviews addicts -
displays are split in half vertically
to use synchronous scrolling matching line numbers.
In short, rotate wide display 90° until its tall.
To improve accessibility of code for those impaired by OLSD,
half-measures like this one can be seen:
Although each function argument is on a separate line,
the indent looks ridiculous.
Why does it have to be strlen("void anyFunctionWithLongArgumentList")-long?
To explain the ridicule of indenting arguments to their function name length,
let’s extend this approach consistenly on entire function body:
intanyFunctionWithLongArgumentList(doubleargumentOne,List<ArbitraryClass>argumentTwoAsList,WhateverClassargumentTree,String...otherArguments){intlocalVar=1;intanotherLocalVar=2;booleanwhateverLongVariableNameWhichShiftsIndentEvenFurther=argumentOne<0&&argumentTwoAsList.isEmpty()&&/************************/argumentTree==null&&/* WASTE OF REAL ESTATE */otherArguments.length==0;/************************/for(ArbitraryClassac:argumentTwoAsList){System.out.pringln(ac);localVar++;anotherLocalVar+=2;}return0;}
A rare healthy person would be tolerant to that above:
Bloody horizontal scrolling has emerged again.
Bloody variable length indent makes no sense.
Indent must be constant1 in length -
every new line can have
either no added indent or +/- single constant shift only:
line 1
line 2
line 3
line 4
line 5
line 6
wrong ugly 7
-void culpritWhichChangesIndent(
- int innocent1,
- int innocent2,
- int innocent3
+void culprit(
+ int innocent1,
+ int innocent2,
+ int innocent3
)
What are these innocent* victims for?
Constant indent keeps innocent* safely unchanged:
-void culpritWhichChangesIndent(
+void culprit(
int innocent1,
int innocent2,
int innocent3
)
Avoiding unnecessary changes goes into deep analysis in the next section.
Paranoid change tracking
Writing code less prone to merge conflicts reduces
the ultimate cost - human time.
The opposite causes merge conflicts and develops OLSD.
Ideally, two changes for unrelated features should cause no merge conflicts.
To see direction leading to the problem, imagine an extreme case -
entire application code is written in a single line (“single line app”).
No changes can be made in parallel because every change causes conflict
and conflict causes rewrite of all lines (because it’s “single line app”).
A less extreme example which can constantly be found in the wild:
Regardless how many versions/years back CODE_1 made into SupportedCodes,
git blame for the code above will always show
only the latest change of the entire enum set.
Without paying human time and scanning both +/- lines,
the patch literally says “everything was changed”:
Statistically speaking,
the more line is responsible for - the more likely it is changed:
scope of code reviews grow larger
(more bugs to slip through)
true authors will not be seen
(to ask, blame or praise)
in source HEAD
automatic merging is more likely to fail
(more human time to waste)
The “single line app” extreme case is extreme,
but there are syntaxes where lines are impossible2 to break
(e.g. CSV, Markdown tables, or even grep-able log records)
resembling visual formatting.
Then, even changes touching independent columns
will make entire rows unmergeable
forcing human-time-costly rework.
To see direction leading to the solution, imagine another extreme case -
entire application code is written with single lexical tokens per line.
To improve coverage, partially evaluated long overloaded lines
require figuring out which part was partial.
Simple short lines are unlikely to be partially evaluated -
no investigation, human time saved.
Error message by language parser often reports line only.
Moreover, line is a universal pointer in IDE/editor integration with
any reporting tool to auto-highlight relevant code.
Single line comment syntax is more wide-spread than other options.
And single line comment can easily target more relevant code part
when expression components are split per line.
doublea=abs(// We use `3` out of good mood.3*sin(y)-// There is no reason why `7`.7/(x-2))/2;
Code analytics relies on lines to derive many statistical values.
Getting closer to “single responsibility per line”
turns line count into cleaner “statistics of complexity”3.
Lines do not inflate the code (no added redundancy) while
future non-architectural changes appear more focused and comprehensible.
Text editors…
Even text editors hardly support “go to column” shortcuts -
only lines are truly “go to” addressable.
There are even special shortcuts to delete single line.
What kind of convenience does it provide if code is not OLSD-friendly?
And, again, points detailed in previous sections:
Patches look clearer and more comprehensible.
More code history gets preserved avoiding overrides.
Only relevant lines tend to be touched for code review saving human time.
Automatic mergeability is more likely.
Once lines are viewed as nested lists,
the mental block is removed
and many normal people start growing lists vertically
exhibiting behavior attributed to OLSD.
Order of priority
Any coder should “please” 3 groups:
Parsers are pleased unavoidably by
writing correct syntax.
Other tools are pleased by
splitting more code lines with constant indent.
Other coders are pleased by
decorative whitespaces for style.
And OLSD influence nervous system to
respect each group in exactly that order of priority.
What’s left for style?
OLSD turns humans significantly insensitive to stylish whitespacing.
Qualities are paramount,
therefore, style is disregarded until after:
Enough lines are broken
This is not a style, this makes tools work for human.
Constant indent is applied
This is not a style, this makes sense.
To explain what stylish whitespacing is,
it’s simpler to explain what it is not:
Places for line breaks.
Not every lexical token deserves successive line break.
All code is a list of lexical tokens -
the very existence of OLSD manifest it with
strong uncomfortable sensation to break lines between these list items.
Line break (a whitespace), however, is not a common syntactic choice for
list item delimiter - additional token is used in between:
Function argument list use , (comma) as a delimiter:
All these sacrifices exist simply because list delimiter (&&)
demands subsequent list item. Think! This need is artificial
(made up by healthy population which does not care about OLSD).
Why Erratic?
{inta=1;doubleb=someFunction(a);;;;// <= Blanks in `;`-delimited list of statements before `}` are valid!}
You don’t bother to remove ;
from the last statment in a block before closing }, do you?
Then, why bother removing last && or + in boolean/arithmetic expression?
It may seem that operators like
boolean && or arithmetic + are not list delimiters.
And what would be the argument against && being list delimiter?
Why not accept the opposite?
What if all delimiters are operators for concatenating different lists?
If mathematicians were coders for centuries,
they would agree to compile tail operators out or
treat them no-op by now:
// List of lines generically ending with `+`:intresult=a+b*c+d*e+f+h-i-j+k+l*n+// <= Last `+`-delimiter with "blank operand" can be no-op!;
TETD is utterly irregular unnecessary special case:
Sometimes TETD is a must
(; at the end of statment).
Sometimes TETD is a must-not
(+ in arithmetic expression).
Sometimes it is optional.
It’s surprising that (e.g. in current Java syntax) enum items
can actually keep troublesome errant trailing delimiter:
enumSupportedCodes{CODE_ZERO,CODE_ONE,//...CODE_EIGHT,CODE_NINE,CODE_TEN,// <= Hey! Designed by OLSD.// <= Blank element after last comma is compiled out.;};
Not only TETD is annoying,
the way such special cases are inconsistently maintained
perhaps holds us back as species.
Constant indent just has to be that:
constant (e.g. 1, or 2, … or 7 spaces).
A line never increments/decrements indent by more than this constant.
Any indent level should be reachable by single increments -
forward or backward:
And don’t get mental, but 4 spaces is a widely used,
even standardized and enforced in some languages.
Another point is “spaces not tabs” simply because spaces are shown
the same way everywhere regardless of the settings
(which may not be accessible, for example, on the web). ↩
Examples of “unbreakable line” syntaxes are often for data formats only:
CSV records are widely used due to open-ability by Excel and
ease of parsing. Avoid them for any long-term use, if possible,
or generate (e.g. from JSON, YAML, …).
Log records are often kept as single line record
(to associate timestamps, level, message, etc.)
to easily grep relevant lines only.
They are less relevant in the context of OLSD because nobody
changes them and most of their data are never read.
Gherkin tables used for Cucumber tests.
When tables are comprehensive enough (good thing),
they may impair parallel development (bad thing) because:
(A) branch is incomplete until tests (tables) are done
(B) every changed test is a source of rework during table merging
Markdown tables of any considerable size
turn wiki into pain for concurrent modifications.
We all need to deal with Windows occasionally when systems include
client-side non-web-based software. And one of the least mentally intrusive
workflow with Windows machines is automation - isolate yourself from
direct interaction with OS through code modification (IaC).
The code modifies Windows on your behalf
(rather than browsing menus and clicking on options).
To increase the level of comfort,
it’s advisable to use POSIX-like environment with common scripting languages.
And that’s where Cygwin kicks in.
Addressing repeated Cygwin installations
Now, how do we install Cygwin without
involving menu browsing and option clicking?
How do we make it on tens, or hundreds, or thousands
of Windows machines quickly and consistently?
How to avoid lengthy download times during installation?
Is it possible to remove the dependency on Internet entirely?
Luckily, it’s already done.
Official Cygwin setup.exe already supports pre-downloading of
selected packages and installing them offline (from pre-downloaded content).
Offline content delivery
Unfortunately, Cygwin setup.exe still requires a living Windows machine
to run and produce the pre-downloaded content.
What if we could do it all on Linux?
Until deployment to target Windows is about to start,
using Windows may be completely avoided.
I’ve been through attempts to automate the creation of the pre-downloaded
Cygwin archives in the past. It was a painful scripting
in Windows batch files (*.cmd) -
a walk through the mine field of bug introduction.
It turned out that Wine on Linux can execute Cygwin setup.exe
without noticeable issues. So, when I learned that Windows is not needed
(until the very moment of deployment, as a target),
this small project appeared - cygwin-offline.
It is a collection of scripts for Linux with Wine to prepare
Cygwin package with user-selected pre-downloaded content.
In fact, you can even install Cygwin on Linux with Wine,
but this is beyond the purpose of this post.
And who would need Cygwin on Linux anyway?