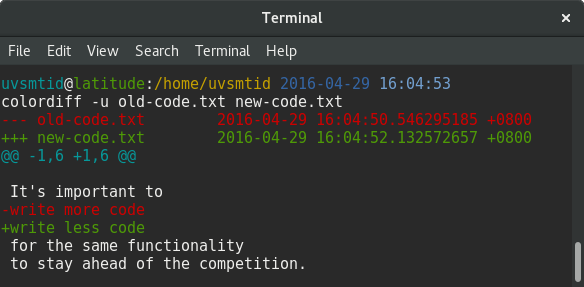
When we talk about software-intensive systems, there is an emerged trend abbreviated as DevOps.
And there are many DevOps aspects which basically
converge into the single phrase - “innovate automate or die”:
One part of it I value above all is Infrastructure as Code (IaC).
Seriously. IaC is the practical way to organize operations change process. Otherwise, DevOps becomes a meaningless hype.
What’s in the concept of IaC?
The idea is as old as life.
Let’s take a look at the DNA. DNA drives execution and reproduction of any kind of complex beasts.

DNA is not the beast. It only indirectly defines it.
A hand-made bird may look like a bird, but it won’t reproduce - there is no DNA for such species.

The alternative to a hand-made bird is some proper gene engineering defining required bird. Pre-engineered DNA for a bird can be used to replicate multiple instances of the same species with little efforts.
Code is the DNA-like indirect approach to building entire systems. Ideally, nothing changes in the system architecture without modifications in its code.
Code compilation worked this way since the beginning - you don’t change machine code directly - instead, you change the source code (DNA) and re-build the binary (the beast). IaC additionally defines your networks, hosts, platforms, and other resources through code.
Again, only code (DNA) keeps evolving. The infrastructure can never be changed directly - it can only be re-instantiated.
Excessive Labor => Process Control
If you write code, it is executed by machines.
The more machines execute, the more humans can afford to think about better solutions.

Machines save the ultimate resource - human time.
There are basically two choices:
-
The repetitive work done by machines will continuously amortize the cost of “unproductive” human time to make these machines.
-
The repetitive work done by humans will only frustrate humans.
Highly frustrated humans escape or take legal action, rise against and rebel, sabotage the results of work.
Practice shows that the more elaborated the setup is, the cheaper it becomes over its entire lifecycle to control the changes with code.
And machines have never risen against humans.
Wasteful Documentation => Concise Introduction
If we go back to pre-DevOps days, what we saw was a collection of applications. Each application was defined by changing its source code.
Everything outside these islands of executable application code was glued by a pile of documentation executed by humans:
- design,
- scaling,
- networking,
- installation,
- configuration,
- updates,
- recovery,
- …

The fewer procedures are automated:
- the more work is pushed to humans repetitively,
- the more overwhelmingly detailed documentation has to be written,
- the more difficult it is to review/verify/test,
- the more human-time is spent,
- the more costly the project becomes,
- …
Picture how documents lose any value:
- They choke both human readers and human writers.
- They are outdated and not trusted.
With code:
- Documents become a mere introduction to intentions to set up a context for humans.
- System infrastructure code is always updated to glue the islands of application code.
Documented intentions are more concise and more stable than any implementation or even design.
Costly speculations => Exact descriptions
What is wrong with nicely written colorful diagrams listing system components, their properties, and descriptions?
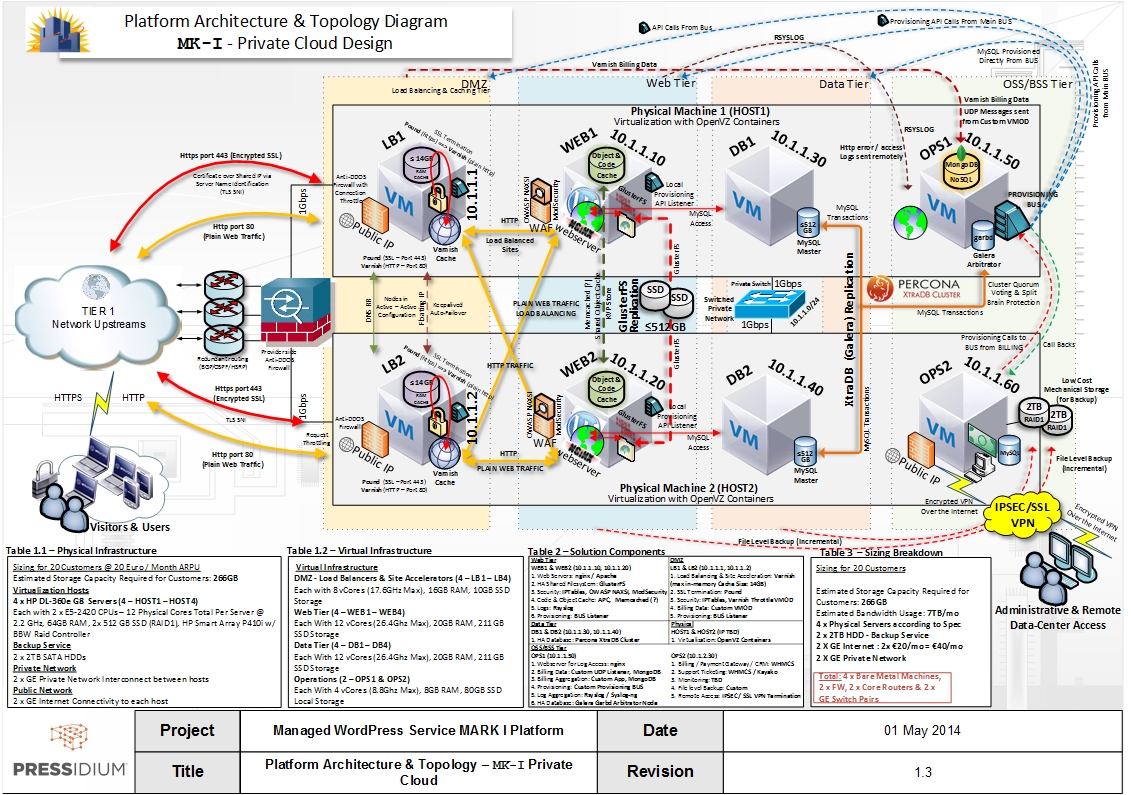
-
Documents misrepresent real system.
A system architecture is “multidimensional” with inter-related projections which tend to be described by various types of documents (dependencies, configuration, operation, recovery, …).
These types of documents (projections) keep becoming inconsistent with every system change.
No one ever did anything using precisely only documentation (without re-evaluation, discussion, guessing, workarounds, etc.).
-
Documents make update process prohibitively inefficient.
The solution is to use machine-processible system description (code) as the primary source of truth. All projections can be generated from that.

You cannot hide inadequacy, inconsistency, incompleteness from a machine in code.
If you want to face the real complexity of your system, try to explain it to a machine and see all the flaws right away.

There is always an understandable proportion of people who want to know something but cannot deal with code.
- Can they deal with details anyway?
- Or maybe an introduction to intentions (possibly on a whiteboard) sufficient enough?
Basic Integration => Rich Functionality
One of the characteristics of open source projects is independence and reduced reliance on others - instead, they provide excessive flexibility in their configuration to integrate.
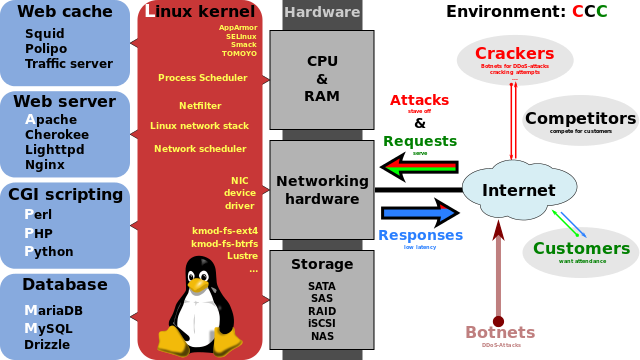
Manual integration is only sustainable with “keeping it simple” approach.
How simple can it be before you start missing required features?
For example, the standard LAMP stack exposes a massive configuration space. The abbreviation still excludes any other necessary operation support:
- Backup and recovery;
- Application update procedures;
- Encryption key management;
- Firewall rules and tightened security;
- Authentication services;
- Logging and monitoring;
- and more …
Don’t get me started about clustering multiplying all that…
Code can turn the mess into organized, deeply integrated solution.
Divergent builds => Identical rebuilds
Again, the ultimate cost of everything is human time. And it is more directly apparent in the software industry.
Give the same instructions to the same human twice, and he/she will execute them differently every time.

-
There is no trust that two copies made by human are identical.
Verifying sameness may pose an insurmountable threshold of human-intensive activities.
-
A machine, on the contrary, trivially executes the same instructions exactly the same way any number of times.
And this assumption is trustable.
Moreover, once a machine “knows” how to build, its “knowledge” cannot degrade.
Needless craftsmanship => Useful innovation
Hand-made instances are naturally unique.
However, nobody appreciates craftsmanship leading to needless excessive efforts with reduced output quality.
What if competition employs automation to get the best of both worlds?

Redefine craftsmanship - think code:
-
Machines become intensively busy
(otherwise, why did you buy them?)
… producing cheap instances.
-
Humans become innovatively busy
(otherwise, why did you
buy thempay them?)… increasing the value of the code.
Code is an opportunity to escape from competition making threshold to enter the market much higher.
Unrecognized Rework => Explicit Iterative Development
It is a fallacy that system is built only once.

You need a plant to produce a car. And both have to evolve.
Creation of a build often requires much more complex environment then deploying that build.
At least build-time tools have to be integrated - they simply do not exist in the production environment.
There are always prototypes, components, and sub-components, their versions - everything is set up one way or another.
And engineering environments better be independent:
- development X number of developers,
- testing X number of maintained versions,
- production X number of customers.
All environments (experimental, staging, demo, stable, production, …) evolve concurrently!

The more environments, the more concurrency, the more features to market per time.
The question really is: how many environments can be afforded?
Any serious project will stall due to increased coordination and wait time to access a shared system instance.
-
How often do people interrupt each other, get confused by unexpected results and perform rework?
-
How often such interference go unnoticed and falsely misdiagnosed under wrong conditions?
-
How to remain sure about anything in uncontrollable changes?
The code allows spawning independent environments at any version from early prototypes to final releases tracking the evolution of every detail affordably.
Stored Artifacts => Mergeable Versions
There are several maturity levels of versioning:
-
Store versions of system state images.
Primitive level - it is effectively a storage of backups (see below) which only allow reverting.
-
Compare any two versions.
Intermediate level - it clarifies what exactly makes two versions different.
The difference tells you what you gain or lose by reverting.
Think about it. Without the ability to compare, how would you choose past version to revert to?
-
Merge any two versions.
Advanced level - it enables independent changes (branching). This point has to be elaborated…
Some of the data formats out there cannot be merged easily:
- graphical images and other multimedia data
- spreadsheet tables and other WYSIWYG documents
- various archive files
Unmergeable format means:
- Only one person can ever change it at a time!
- Write access must be exclusive locking everyone else out!
- All updates must be sequential!
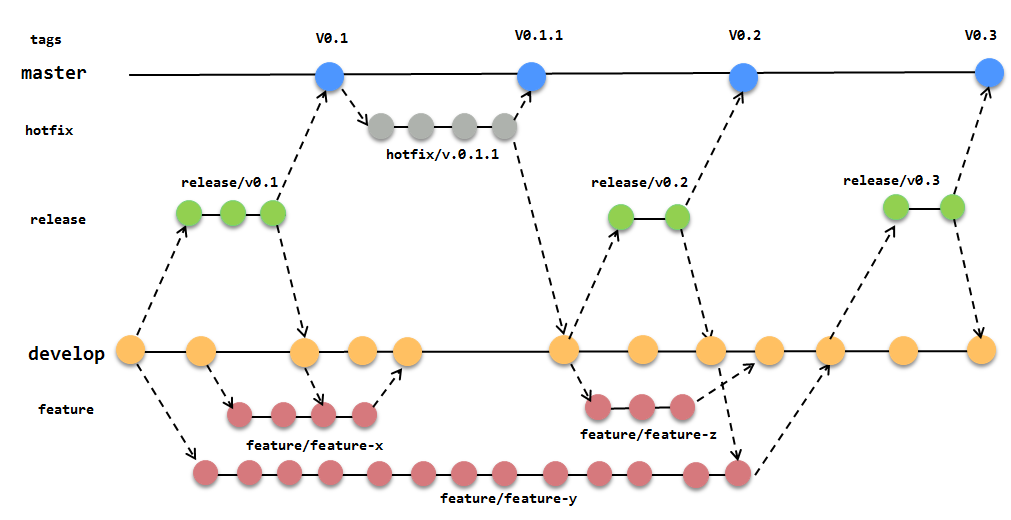
Why would you branch if you cannot merge? Think about it.
Merge-ability is paramount!
Now, it may seem merging is commonly available. Nope. In general, it is extremely tough to implement.
Any code is a mergeable plain text. It seems like a primitive format, but its merge-ability allows advanced parallel workflows supported by a myriad of tools.
Scattered copies => True reuse
The same functionality re-occurs in different subsystems. And its direct re-implementation multiply rework on every subsequent update.
For anyone who avoids rework in software, it is a very well known problem and solution.
-
Problem:
Template copying. -
Solution:

Factoring out.
Code implies both the problem and the solution. Copying implementation has only the problem alone.
Onsite Development => Location-independent offline activities
Manual approach requires direct (onsite) access to the system environment to change it.
And what if remote access is not always available? Traditional direct manual updates become impossible.

The code can be developed, reviewed and delivered without immediately available environment necessary for it to run.
Applying the code to the target isolated environment is done at the earliest convenience.
With code, the development becomes:
- offline and location-independent,
- isolated from conflicts and independent of downtimes introduced by others.
Unseen distributed changes => Centralized management
For any system including more than one node, the configuration becomes distributed.
Over the time it will be increasingly difficult to comprehend what set of resources on which node are essential.
On the other hand, the code is always managed centrally. And tools distribute resources automatically and precisely according to various executable conditions.
Centralized management via code may be the single most important factor to eliminate laborious verification and mistakes.
Higher Level Automated Testing
Integration tests are normally bound to a single target environment.
If code describes the system, any environment is few moments away. Even architectural and scaling changes may be covered by automated tests (number of nodes, their roles, network layout, etc.).
Reviews and Demos
Do you practice reviews or demos? And how exactly are these processes made frequent and practically possible?
You may suffer from the fact that there is simply no environment to demonstrate deliverable functionality.

With code:
-
The demo is performed on a separate system fully instantiated on demand with machine-precision - you will see it now interactively.
-
Reviews are facilitated by highlighted and detailed code changes.
Worry no more - details are never forgotten, but you may choose to ignore them.
Recovery
Parts of the system will inevitably need recovery.
Even before it is a hardware problem, a human may more likely introduce undiscoverable braking change manually.

Can you tell how long it takes to recover?
The question goes beyond any crucial production site. A project may include development and testing teams with their operations - the progress stalls on failures in their environments.
You may think about system redundancy, but redundant instances have to be maintained and precisely restored to make the system fault-tolerant again.
Apart from disaster recovery, there is almost a daily operation to reset environments to its previous versions or versions deployed for a particular customer.
With code, environments can be easily rebuilt and recover.
Security
Consider also “dirty state” as a security threat:
- leftover notes,
- temporary allowed connections,
- unaccounted data copies,
- test encryption keys,
- weak passwords,
- unused accounts,
- …
If the system is compromised, the instances keep all these backdoors left unidentified and wide open.
With code, clean systems can be easily rebuilt preemptively.
Backups can hardly serve this purpose because “dirty state” cannot be selectively excluded.
Backups versus Code
Backups are the straightforward approaches to recovery.

-
Backups are huge and slow.
Compare mammoth with its DNA sample.
You can still easily justify a backup for actual application data - something which is not re-generatable and precious.
However, system instances should be re-generatable.
The code stays slim for that purpose - any version recoverable anytime.
-
Backups are not comparable and mergeable.
You cannot compare or merge two mammoths, but it’s possible to select their best properties in combined DNA.
-
All backups may be already contaminated.
Imagine all hibernated mammoths you store in the freezer were terminally ill before they got there because of DNA. Without the ability to clone their DNA and fix it, they are lost as species.
The code hardly has any limit of depth into its history to patch it against issues.
Backups actually complement swift automated recovery but surely unable to provide all the benefits alone.
Besides all that, backups require managing them - a sub-system. Shouldn’t it also be codified for automation instead?
Hidden Issues => Actionable Reports
If steps are executed manually (without costly pedantic review):
- Exit codes are not seen.
- Error messages may remain unnoticed.
- The sequence of steps and their dependencies are violated.
If valuable feedback is not seen immediately, the chance to eliminate hazards early (away from the release dates) is missed.
The potential problems pile up, and most of them are not even recognized.
- Did you get deployment report with all failed steps listed down?
- Can you redeploy again and review a fresh report right now?

Any automation instantly reports about a spectrum of issues across the entire integrated stack every time.
Reports are factual, precise, detailed, human-friendly and machine-processible.
Blind Troubleshooting => State Analysis
Troubleshooting requires reliable evidence and ideally in a preserved environment isolated from concurrent actors.
In its extreme worst case, the evidence is made up by humans.
The more unreliable evidence is:
- the fewer causes can be ruled out quickly,
- the more human-time is spent on making things sure (instead of implementing a solution),
- the more deadlines are crossed,
- the more costly the project becomes.
And this chain may loop on every issue encountered!
Code allows cheap identical isolated environments with pre-configured sophisticated tooling to capture runtime state.
Instead of guessing, you are analyzing!
Hesitant Steps => Resolute Progress
Have you seen teams who avoid changes because they cherished single working setup?
Systems maintained manually accumulate all sorts of unknown modifications - configuration drift. Nothing works without this change, but nobody remembers what they are.
Do not let demands for stability freeze down any future progress.

A system code under revision control is undamageable and tracks all changes between versions with the finest granularity.
Spawn a system instance of any branch and maintain progress.
Conclusion
Let’s list the activities per section of this post:
- control effortlessly
- document lightly
- describe exactly
- integrate deeply
- build repetitively
- craft innovatively
- multiply identically
- version naturally
- reuse truly
- develop independently
- manage conveniently
- test thoroughly
- preview interactively
- recover proudly
- secure reliably
- backup reasonably
- report comprehensively
- troubleshoot analytically
- progress predictably
These are very powerful capabilities. In fact, entire Agile movement (which is normally an empty hype by itself) is derived from these properties.
- Everything above is enabled only by managing Infrastructure as Code.
- Everything above is largely disabled by doing it otherwise.
It might be logical do to Everything as Code (EaC). However, there are limitations worth a separate post.